
Case Study: Fintech Rebuild with AI — Workflow Spec to Production Code
A composite fintech CTO case study: how Relis-extracted workflow specs became prompts for Cursor and Claude Code in a SOC 2 environment, where AI helped, and where humans drew a line.
23 min read
The composite CTO at the center of this case study runs a roughly twelve-engineer team at an early-stage fintech serving small business lending and payments. The company started on Bubble.io because the original founders were not engineers and needed to ship a working product to underwriters before the seed round closed. Two years and one Series A later, the company faced a SOC 2 Type II audit, regulator questions about workflow traceability, and a hiring market that did not include senior backend engineers willing to inherit a Bubble app. Migration stopped being a someday decision and started being a deadline.
What makes this case study worth writing is not the fact of the migration — it is the way AI coding tools were used inside a regulated environment without the team losing the audit trail. The marketing for Cursor, Claude Code, and similar tools tends to emphasize speed; the regulated reality is that speed is the second-most important property after explainability. This article walks through how that team handled the trade-off: which decisions were translated into AI prompts, which were not, and how the Relis-extracted workflow spec became the input that made the difference between AI as a productivity tool and AI as a compliance liability.

Why Bubble First, Why Migrate Now
The original product hypothesis was that small business owners would tolerate a thin underwriting interface if it returned a credit decision in under ten minutes. That hypothesis took two non-engineer founders, one Bubble subscription, and three months to validate. Bubble was not a strategic platform choice — it was the only tool that lets a former product manager and a former operations lead ship a multi-step underwriting flow without hiring a backend engineer first.
Two years on, the same Bubble app was carrying loan origination volume that no one had imagined when the data types were drawn up. The migration triggers stacked, in roughly this order: workload-unit costs that started outpacing customer growth on a unit-economics basis, a Series A board that asked for SOC 2 Type II by a fixed quarter, a payments processor partner that started asking about webhook idempotency guarantees, and a senior engineer hire who said in the second interview, "I will not own a Bubble app." None of these alone forced the call. Together they did.
"The trigger was not a single thing. The trigger was looking at four separate problems and realizing they all had the same answer." — Composite CTO, synthesized from advised fintech engagements
For more on how the underlying architecture stress points compound, see the four-layer anatomy of a Bubble app — every fintech we have advised has hit at least three of those layers as migration triggers, and the regulated context turns the workflow layer into the binding constraint long before workload units do.
Across the engagements that fed this composite, the median time between "we will migrate eventually" and "we are migrating now" was roughly six weeks — and the trigger was almost always a compliance or audit deadline rather than a performance ceiling. Performance pain causes annoyance; audit deadlines cause calendars.
Why AI Coding Tools Make Sense Here, and Where They Do Not
Once the migration was committed to, the team had to decide whether AI coding tools would be part of the build or sit outside it. In a non-regulated environment this is largely a productivity question. In a regulated environment it is an evidence question: every line of code that touches lending decisions or money movement needs to be explainable to an auditor, and "we used Cursor" is not, by itself, an explanation. So the team evaluated AI tools the way they evaluated any vendor — what does the audit log look like, how is access controlled, what is the model retention policy, and what happens when a regulator asks for a chain of custody on a specific function.
The team did not pick one tool and standardize. Cursor was used for refactor passes and structural translation where the model could see the whole repo. Claude Code was used for backend workflow translation, where the input was a long Relis-extracted spec and the output was a Pull Request scaffold. GitHub Copilot was kept on for in-line completion in editors where the engineers preferred it. The pattern was: each tool had a role, and each role had a different audit story.
| Criterion | Cursor | Claude Code | GitHub Copilot |
|---|---|---|---|
| Audit log granularity | Per-edit history in repo, plus chat transcripts | Session transcripts, shell command log, file diffs | Inline suggestions; less structured trail |
| Spec-to-code from long input | Strong with repo context; spec must live in repo | Strongest with very long workflow specs | Designed for line-level autocomplete, not spec ingestion |
| Model and data retention controls | Workspace-level controls available | Enterprise tier with retention controls available | Enterprise tier with retention controls available |
| Best-fit task type | Refactor and structural translation | Workflow spec to PR scaffold | Inline completion inside review-bound code |
| Where the team did not use it | Anything touching auth or KYC decisions | One-shot generation of payment-rails code | Code that needed to be defended line-by-line |
"We did not pick a tool. We picked which tool gets which job, and we wrote it down. The audit log was the first deliverable, not the code." — Composite CTO, synthesized
The decision the team rejected was the obvious one — let AI write the loan-decision logic from a description. They never let it. Loan decisions, KYC integration logic, and webhook signature verification were always written by a human first, then optionally refactored by AI under review. Everything else — schema, CRUD, pagination, retry logic, idempotency keys, queue scaffolds — was treated as fair game for AI generation, because everything else is the kind of code that good specifications make boring.
The Workflow: Relis Outputs to AI Prompts to Pull Requests
The workflow that emerged after the first month looked nothing like the marketing demos. It was not "describe the feature to Claude and accept the output." It was a four-station pipeline that turned an extracted Bubble blueprint into reviewed, merged code. The point of the pipeline was to make AI a known step in a known sequence, not a magic substitute for engineering judgment.
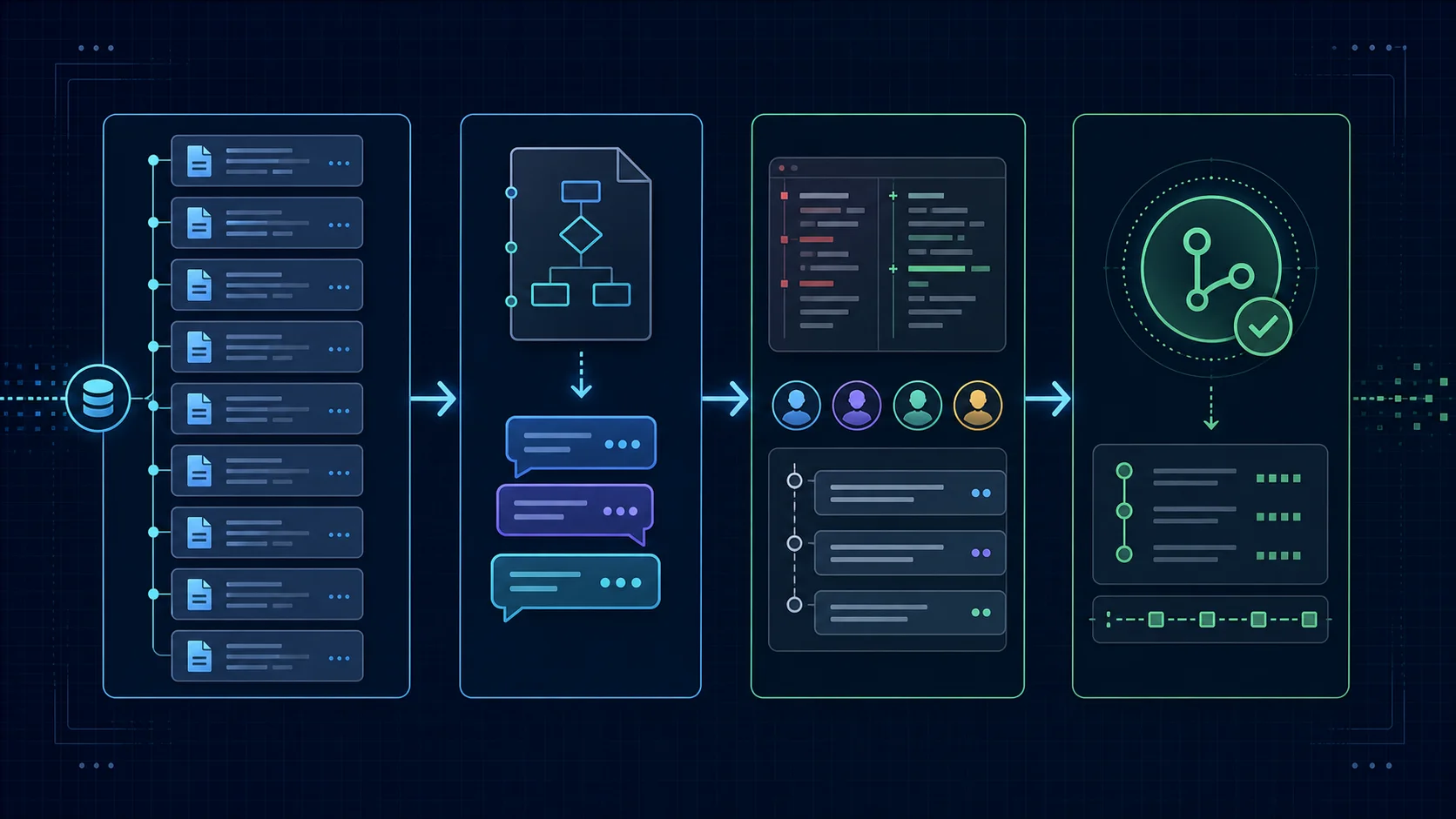
Station one was Relis extraction. The team ran the full extraction on the Bubble app and got the nine standard outputs — ERD, data structure inventory, API connector specs, backend workflow inventory, privacy rule documentation, app settings, and so on. The extraction itself took about ten minutes. The extraction outputs were committed to a private repo as Markdown so the workflow specs lived next to the code that would replace them. This single decision — putting the spec in source control — was the one that made the audit story coherent later. For the underlying argument that AI cannot do migration discovery, only migration development, see the documentation-first AI workflow guide.
Station two was prompt construction. The engineers wrote prompt templates that referenced the spec files directly. A typical Claude Code prompt opened a session in the repo, attached the relevant Relis-extracted workflow document as context, attached the target framework conventions document, and asked for a Pull Request scaffold for a single workflow at a time — not the whole inventory. One workflow per PR was the discipline the team kept the longest.
Station three was human review. Every AI-generated PR went through code review by an engineer who had not been in the AI session. The reviewer's job was to look at the diff against the spec — not just at the diff against good practice. If the spec said the workflow had three branches and the AI produced two, that was a review failure regardless of how clean the two branches looked. Reviewers were instructed to leave inline comments referencing the spec section by line number. This produced a side benefit: the spec became a living document because reviewers caught spec gaps that the original Bubble app had hidden.
Station four was merge and log. Merged PRs were tagged with a commit trailer that recorded which AI tool had drafted which sections. The trailer was a one-line convention — for example, AI-Drafted-Sections: backend/workflows/origination_decision.ts (Claude Code, session id abc123). The trailer was not enforced by tooling at first. After the second compliance review, the team added a pre-commit hook that required the trailer when the diff matched the AI-touched paths.
"When the auditor asked, 'how do you know what AI did,' I did not have to dig. I ran git log with a grep and handed them the trail. The audit log was the workflow spec plus the commit trailer plus the review thread. Three artifacts, one story." — Composite CTO, synthesized
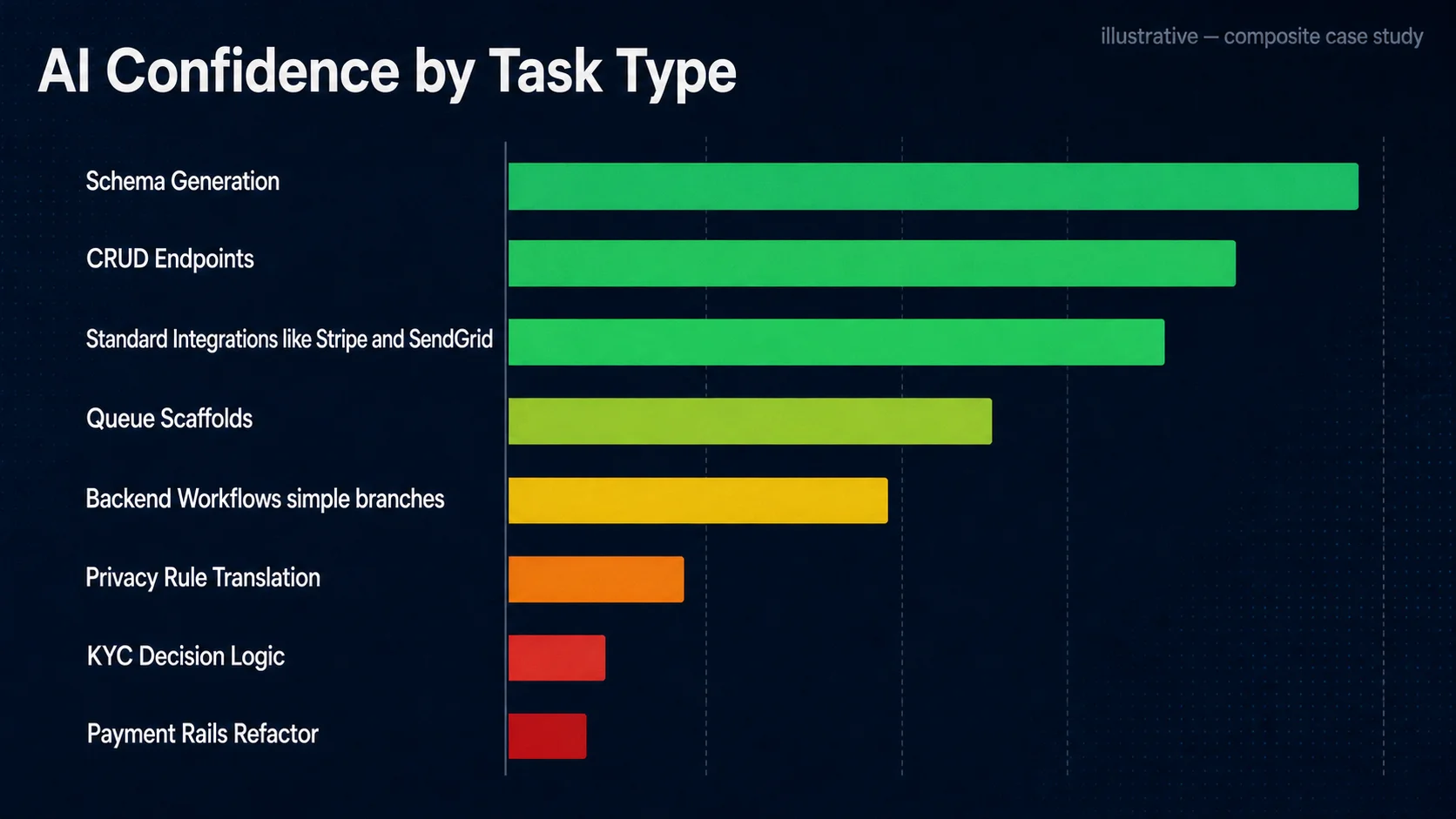
Where AI Failed, and What We Learned
Two failure patterns showed up early enough to be useful, and one failure pattern showed up late enough to require a postmortem. Naming all three in public is part of the reason this case study exists; the marketing case studies tend to omit the postmortem.
The first failure was confident hallucination on partial input. In the third week the team gave Claude Code a workflow spec that had been lightly redacted — a few constants and IDs replaced with placeholders. The output filled in the redacted constants with plausible-looking values that compiled and even passed the smoke tests, because the placeholders were not type-checked. The pattern landed in a feature branch and would have been merged if a reviewer had not noticed that one constant was a known regulator-side identifier the team did not have. The fix was procedural: redactions were replaced with explicit "REDACTED — fill in from secrets manager" tokens that the linter rejected at commit time.
AI tools are very good at filling in plausible values for missing constants. In a regulated environment that is exactly the wrong superpower. Use tokens that are syntactically illegal, not semantically plausible — placeholder strings the compiler or linter refuses to accept are safer than placeholder strings that look like data.
The second failure was implicit privacy-rule loss. The Bubble app encoded several access policies as privacy rules on data types, not as code in workflows. The Relis extraction documented those rules separately, but the workflow-translation prompts were only being given the workflow spec. The AI produced workflow handlers that were correct against the workflow spec and silently incorrect against the privacy spec. The fix was to add the privacy-rule document as a mandatory attachment to every workflow-translation prompt, and to add a static check that flagged any controller endpoint without an explicit authorization annotation.
"It was not that the model was wrong. It was that we asked it half a question. When we attached the privacy spec, the same model wrote authorization-aware code on the next attempt." — Composite CTO, synthesized
The third failure showed up two months in, during a payment-rails refactor. The team had let AI propose a small change to a webhook retry policy. The change was reviewed and merged. Three weeks later, on an unrelated incident review, the team noticed that the retry policy had introduced a corner case where a duplicate webhook from the processor could trigger a duplicate ledger entry. The original spec had specified idempotency by external transaction ID; the AI-suggested refactor had silently shifted to idempotency by request UUID. The reviewer had not caught it because the spec language was subtle. The fix was a postmortem and a new rule: payment-rails changes were no longer eligible for AI-drafted PRs at all. Some categories are not "AI with stricter review." Some categories are "no AI."
Compliance and Audit: How We Stayed Honest
The compliance story is the part that does not fit in a tweet. The short version: SOC 2 Type II was not blocked by the use of AI coding tools, but it required documentation that most teams do not produce by default. The longer version is that the workflow specification, the commit trailer convention, the review thread, and the policy-rule attachment together made AI use auditable in a way that handwritten code on its own usually is not. The auditor's question was never "did AI write this code." The auditor's question was "show me how a change to the origination workflow gets from a decision into production." The answer was a workflow spec diff, an AI session transcript, a PR with a reviewer trail, and a merged commit with a trailer.
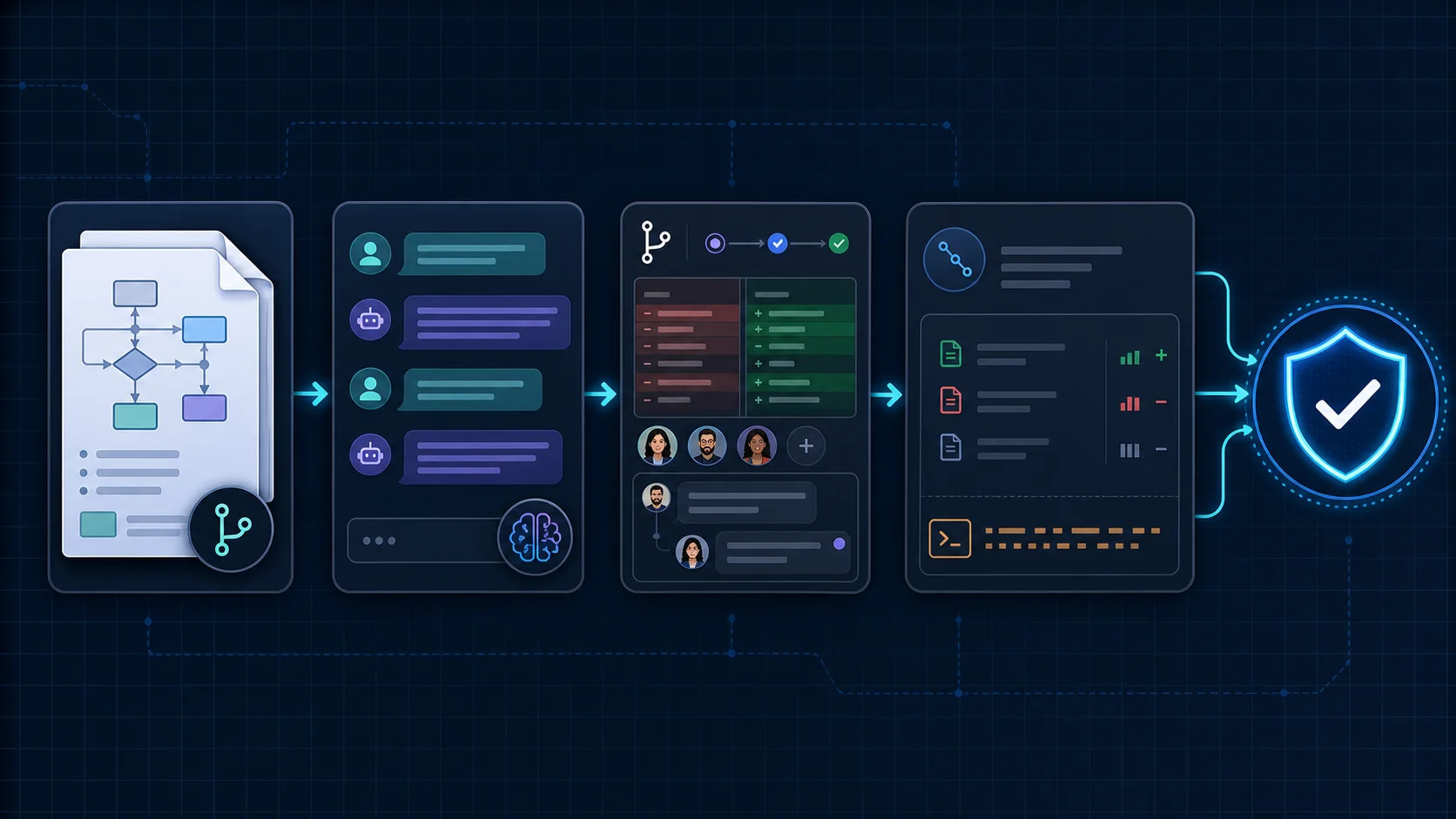
Two policies kept the picture coherent over time. The first was that any AI session that touched the repo had to be initiated from a workspace with retention controls configured — the engineering manager owned the configuration and reviewed it quarterly. The second was that the spec files were treated as compliance artifacts, not engineering artifacts. They were versioned, change-controlled, and required to be updated through a PR rather than edited freehand. This sounds heavy and was, on average, two minutes of overhead per change. It bought back hours of audit-prep time later.
The teams we have seen struggle most with regulated AI use are the ones that try to build an audit trail at the end of the migration. The teams that succeed do one thing differently: they put the spec in source control on day one, and the audit trail emerges from how they were already working. The artifact you need at audit is the artifact you needed at code review.
For the broader argument about why architecture documentation pulls double duty as an investor and audit signal, see the self-audit guide before an investor pitch — the same artifact that defends a SOC 2 review also tends to defend a Series B technical due diligence, because both audiences are asking a version of the same question.
One-Year Lookback: What I Would Do Differently
Twelve months after the migration started, with a substantial share of the Bubble surface area now running on the new stack, the composite CTO's lookback is not "AI was magic" or "AI was a mistake." It is more granular than that. The migration would have been faster with three changes the team did not make until midway, and the pattern is recognizable enough to be worth naming.
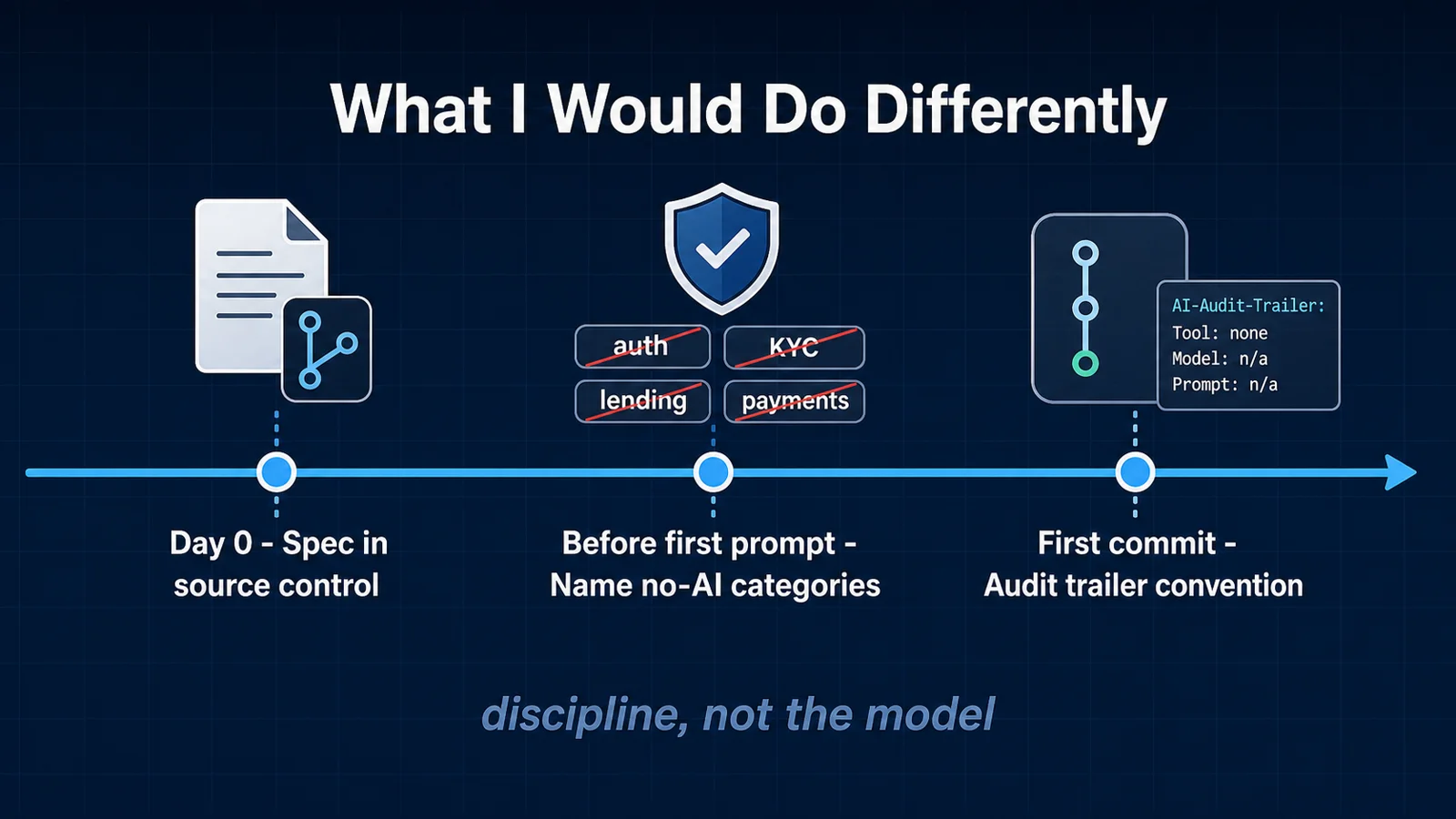
First, treat the spec as the product earlier. The team spent the first three weeks treating the Relis extraction as a reference document and the code as the work. Once they started treating the spec as a first-class deliverable — versioned, reviewed, kept in sync with the code — both the AI output quality and the human review speed jumped. The spec is not the lesser sibling of the code. It is the input that determines whether AI is useful.
Second, name the no-AI categories on day one. The team learned the payment-rails lesson the hard way. The earlier you write down the categories where AI is not allowed to draft — auth, KYC, lending decisions, payment rails — the less you negotiate it under deadline pressure later. The rule should not have been earned by an incident. It should have been a starting policy.
Third, add the commit trailer convention before the first AI commit, not after the second compliance review. Retroactive traceability is an order of magnitude harder than prospective traceability. A two-line pre-commit hook on day one is worth a week of archaeology in month four.
"If a CTO at another regulated fintech asked me what to do, I would not say 'use AI' or 'do not use AI.' I would say: write down which categories AI is allowed to touch, put the spec in source control before the first prompt, and add the audit trailer on the first commit. The rest is just engineering." — Composite CTO, synthesized closing line
Frequently Asked Questions
Q. Is AI coding even allowed in regulated environments like fintech?
Generally yes, but with conditions. Most regulated environments do not prohibit AI coding tools per se — they require explainability, access control, and a chain of custody for changes that touch regulated functions. The case study team handled this with a spec-in-source-control workflow, a commit trailer convention identifying AI-drafted sections, and explicit no-AI categories for auth, KYC, and payment rails. Verify with your own compliance counsel and your auditor — the answer is jurisdiction- and framework-specific.
Q. Which AI tool should a regulated team start with?
The composite team did not standardize on one tool. Cursor was used for refactor passes that benefited from full-repo context, Claude Code for workflow-spec to PR scaffold translation, and Copilot for inline completion. The relevant question for tool choice was not which model is smartest — it was which retention controls and audit logs are configurable at the workspace level. Tool choice mattered less than input quality and review discipline.
Q. How do you handle audit requirements when AI generates code?
The pattern that worked for the composite team was four artifacts that connected end to end: a workflow specification kept in source control, AI session transcripts retained per the tool's retention policy, a Pull Request review thread with reviewer comments referencing spec sections, and a merged commit with a trailer naming the AI-drafted paths and the session identifier. Auditors did not need to understand the model. They needed to follow the change from spec to merge.
Q. What is the realistic failure rate of AI-generated code on this kind of stack?
The team did not run a structured benchmark, so any single number would be misleading. The qualitative pattern was that schemas, CRUD, queue scaffolds, and standard integrations were largely correct on first generation given a good spec; complex conditional logic, privacy-rule translation, and payment-rails changes were not. The numbers in the documentation-first AI workflow guide — roughly 80 percent code volume at high accuracy with structured input, the remaining share requiring rewrite — are consistent with the pattern this team observed. Treat as an order of magnitude, not a forecast.
Q. Does any of this apply if I am not a fintech?
Most of it does. The discipline of putting the workflow spec in source control, naming no-AI categories before the first prompt, and adding a commit trailer for AI-drafted sections is portable to any team that wants traceability — health-tech, edtech with student data, any B2B SaaS with a SOC 2 commitment. The fintech-specific parts are the categories: in another industry, the no-AI list looks different but the principle of having one is the same.
The Spec Is the Product, the Code Is the Receipt
- Migration triggers stack, and the regulated trigger usually wins: Workload-unit costs, hiring friction, and performance pain accumulate, but the audit deadline is the one that puts a date on the calendar. Treat compliance timelines as the binding constraint when planning the migration phase.
- AI tool choice is a role assignment, not a standardization decision: Cursor, Claude Code, and Copilot did different jobs in the case study. The relevant evaluation criterion was retention controls and audit log granularity at workspace level, not model benchmark scores.
- Workflow specifications are the prompt: The single change that made AI useful in this regulated context was treating the Relis-extracted workflow spec as a first-class, source-controlled artifact that fed directly into AI prompts. Vague descriptions produced unusable output regardless of model. Specs produced reviewable PRs.
- Some categories are no-AI categories: Auth, KYC, lending decisions, and payment rails were never AI-drafted in this case study after the team learned the lesson the hard way. Naming the no-AI list before the first prompt is cheaper than naming it after the first incident.
- The audit trail is a side effect of good engineering, not an extra deliverable: Spec in source control, commit trailers identifying AI-drafted sections, and review threads referencing spec line numbers were the four artifacts that made SOC 2 readiness feel routine rather than retroactive.
The teams that get the most from AI in regulated environments are not the ones with the best prompt engineers. They are the ones that wrote the specification first, decided which categories AI was not allowed to touch, and kept the receipt of every AI-drafted change in a place an auditor could read. Migration off Bubble is hard. Migration off Bubble in a regulated environment with AI in the toolkit is harder. It is also, when the discipline is in place, faster than doing it without AI — which is why the composite CTO at the center of this story would do it the same way again, with three changes named in the lookback.
Feed Your AI Tools the Workflow Spec They Need
Relis extracts the workflow inventory, ERD, API connector specs, and privacy rules from your Bubble app — the structured inputs that turn AI from a hallucination machine into a reviewable PR generator. Free for your first project.
Start Free ExtractionYour Bubble App Has No Export Button — Until Now
Relis extracts your complete Bubble.io architecture automatically. ERD diagrams, DDL scripts, API docs, workflow specs — all in under 10 minutes.
Your Bubble App Has No Export Button — Until Now
Relis extracts your complete Bubble.io architecture automatically. ERD diagrams, DDL scripts, API docs, workflow specs — all in under 10 minutes.